
Recovery
Failures and Recovery
Failure Classification
데이터베이스 시스템이 처리하는 장애는 크게 3가지로 분류할 수 있습니다.
- Transaction Failures
- Logical Errors : 트랜잭션 내부에서 발생하는 오류, 사용자의 명시적인 요구
- System Errors : 시스템 내부 결정에 의한 오류(예: Deadlock 발생으로 인한 특정 트랜잭션 철회
- System Failures : Memory 내용이 사라지는 문제(예: 정전, OS 오류, 하드웨어 결함 등)
- Disk Failures : Disk 내용이 사라지는 문제(예: 하드웨어 결함)
시스템이 처리하고자 하는 이러한 장애들은 예고 없이 발생할 수 있습니다. 이러한 장애가 발생하는 경우, 시스템을 복구하기 위해 Recovery 기법을 사용합니다.
Recovery Algorithms
회복 알고리즘은 크게 2가지로 분류할 수 있습니다.
- 정상 상태에서 시스템 회복을 대비하기 위하여 수행하는 연산 : ex) Checkpointing
- 장애가 발생하였을 때 회복하기 위하여 수행하는 연산 : ex) REDO, UNDO
Stable storage
Stable storage는 어떠한 장애가 발생하여도 저장 내용이 상실되지 않는 가상적인 저장소입니다. 이러한 가정을 통해 데이터베이스 시스템은 장애가 발생하더라도 데이터의 무결성을 보장할 수 있습니다.
현실적으로는 안정 저장 매체로 RAID 시스템을 사용합니다. RAID 시스템은 여러 개의 디스크에 저장 내용을 중복하여 저장하고 분산하여 저장하는 방식으로 안정성을 높이는 기술입니다.
Data Location
데이터베이스 시스템에서는 동일 데이터가 3군데 위치에 존재할 수 있습니다. 이러한 데이터 위치는 다음과 같습니다.
1. Main Memory
- Process memory(work area)
- Buffer blocks
2. Disk
- Disk blocks
데이터 버퍼와 프로세스 메모리 영역은 메인 메모리 내에 존재하므로, 메인 메모리가 고장이 나는 경우에는 데이터가 손실되나, 디스크에 존재하는 데이터는 손상이 없습니다.
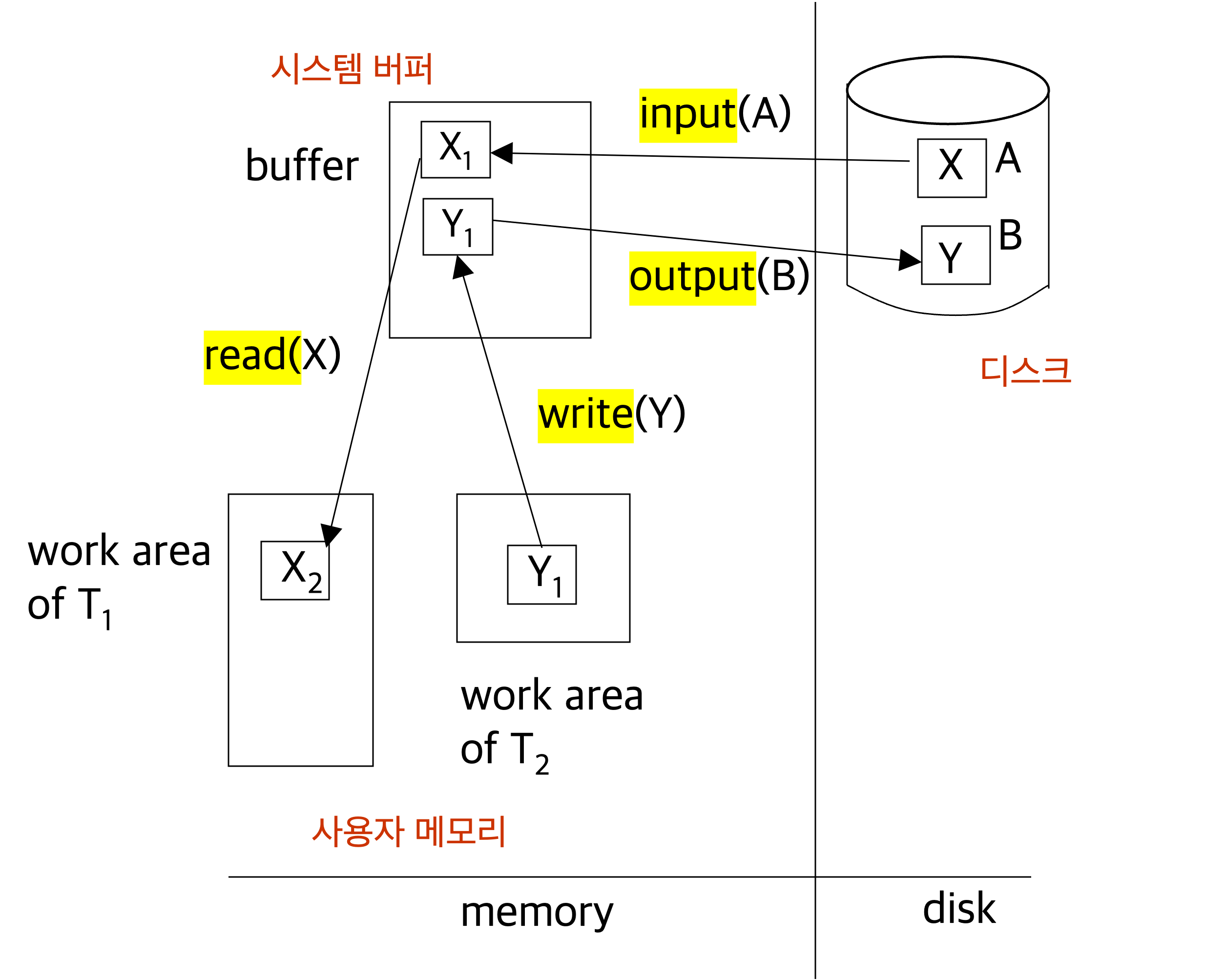
데이터는 기본적으로 디스크에 존재하며, DBMS에 의하여 필요 시에 시스템 버퍼에 블록 단위로 복사될 수 있습니다. (디스크→시스템버퍼 복사)
시스템 버퍼에 있는 데이터를 사용자 트랜잭션이 직접 사용하지 않으며, 사용자가 데이터를 접근하려면 해당 사용자 메모리로 데이터를 복사(read 연산)해 와서 접근합니다. (시스템버퍼→사용자메모리 복사)
사용자는 사용자 영역에 있는 데이터를 접근하며, 데이터 갱신을 하는 경우 시스템 버퍼에 존재하는 데이터 값과 사용자 메모리에 존재하는 데이터 값이 상이할 수 있습니다.
사용자가 write 연산을 이용하여 사용자 메모리에 있는 데이터를 시스템 버퍼에 복사할 수 있습니다. (사용자메모리→시스템버퍼 복사)
세 군데 존재하는 데이터 값이 모두 상이할 수도 있으나, 가장 정확한(또는 최근에 갱신된) 데이터 값은 사용자 메모리에 존재하는 데이터 값입니다.
결론
데이터베이스 시스템에서 프로세스 고유 영역에서 버퍼 블록으로 데이터를 이동하는 것은 데이터베이스 관리 시스템 또는 사용자의 요청에 따라 이루어집니다. 하지만 버퍼 블록에서 디스크 블록으로 데이터를 이동하는 것은 운영체제의 역할입니다.
데이터베이스 사용자가 데이터 쓰기를 완료하는 것은 버퍼 블록에 데이터를 쓰는 것임을 알아야 합니다. 즉, 쓰기가 완료된 후에 시스템 장애가 발생하면 디스크에는 아직 데이터 갱신이 반영되지 않을 수도 있습니다.
Recovery approach
회복 기법은 크게 두 가지 방법이 존재합니다
- log-based recovery
- shadow paging
그 중에서 로그 방식(1)이 상용 DBMS에서 많이 사용됩니다.
로그는 데이터베이스 시스템에서 발생하는 모든 변경 사항을 기록하는 파일입니다.
로그 파일은 안정 저장 매체에 저장되어야 하며, 데이터베이스 시스템이 장애가 발생하였을 때 로그 파일을 이용하여 데이터베이스 시스템을 복구합니다.
로그 방식에서는 DB에 변화가 발생하기 전에 로그 파일에 변경 사항을 기록해야 합니다.
이러한 방식을 Write-Ahead Logging(WAL) 이라고 합니다.
2. shadow paging
shadow paging은 데이터베이스의 모든 페이지를 복사하여 변경 사항이 발생할 때마다 새로운 페이지를 생성하는 방식입니다. 이러한 방식은 로그 방식에 비해 비효율적이지만, 복구 시간이 빠르다는 장점이 있습니다.
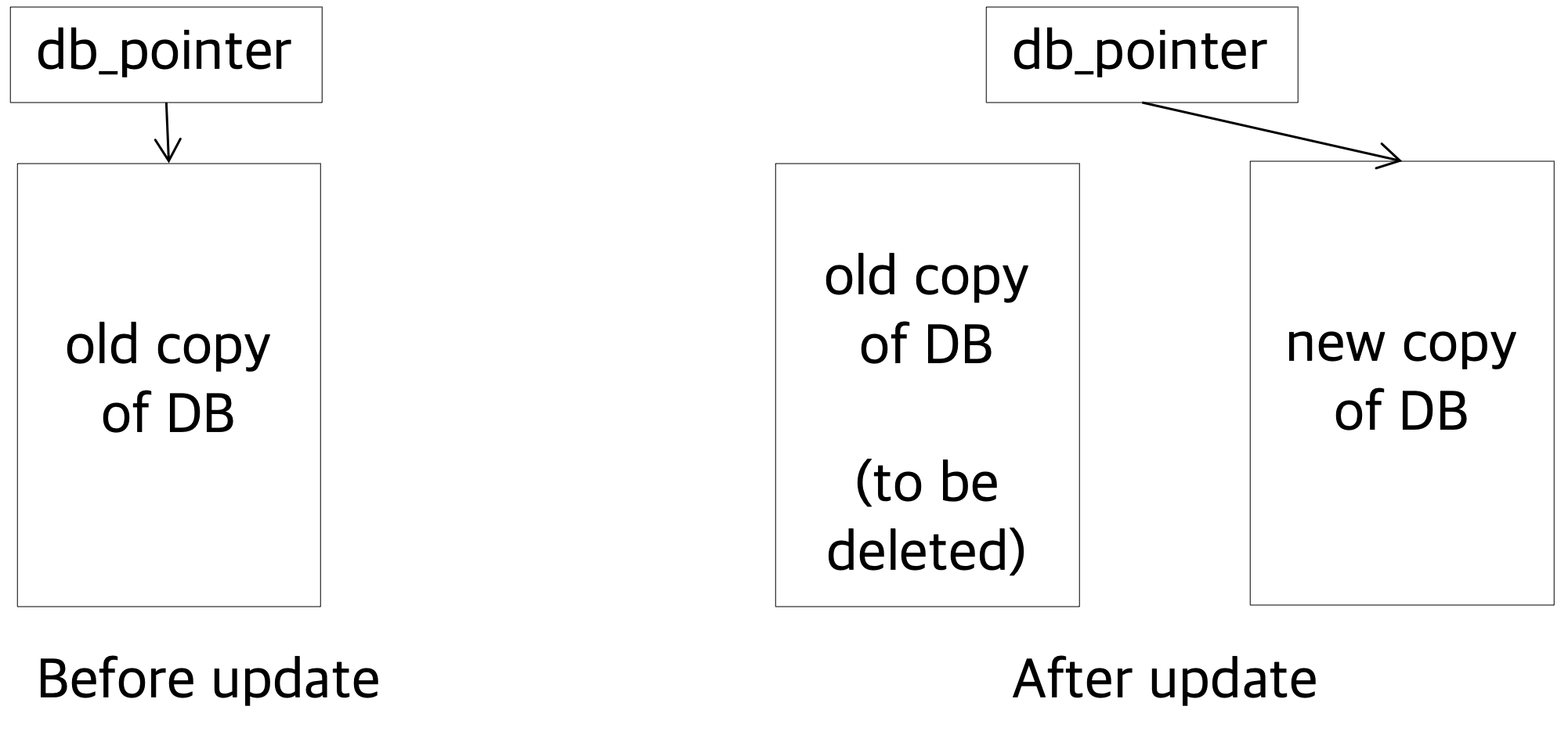
- update가 발생하면 copy본을 만들어서 db_pointer를 옮깁니다.
- recovery가 필요하다면 db_pointer를 원래대로 돌리면 됩니다.
하지만 DB의 크기가 커질수록 shadow paging은 비효율적입니다.
그림자 기법은 오래전에 사용되었던 기법으로 요사이는 데이터베이스 환경에서는 사용하지 않습니다.
1. Log-based Recovery
로그 기반 회복은 데이터베이스 시스템에서 발생하는 모든 변경 사항을 로그 파일에 기록하는 방식입니다.
Normal Processing
로깅을 함에 있어 구체적으로 어떤 값을 어떤 방식으로 기록하는가는 여러 가지 방식이 있습니다.
<Ti start>: 트랜잭션 Ti가 시작됨을 기록<Ti, X, old, new>: 트랜잭션 Ti가 데이터 X의 값을 old에서 new로 변경함을 기록<Ti commit>: 트랜잭션 Ti가 종료됨을 기록
디스크와 메인메모리 간의 데이터 이동이 블록 단위로 이루어졌듯이, 로그 레코드를 디스크에 기록할 때도 블록 단위로 이루어집니다.

트랜잭션은 동시에 다수가 실행되므로, 로그 블록 하나 내에는 여러 트랜잭션의 로그 레코드가 존재할 수 있습니다.
Checkpointing
 Checkpoint는 데이터베이스 시스템이 정상적으로 동작하고 있는 시점을 기록하는 것입니다.
Checkpoint는 데이터베이스 시스템이 정상적으로 동작하고 있는 시점을 기록하는 것입니다.
데이터베이스 시스템이 장애가 발생하였을 때, 복구를 위한 기준점으로 사용됩니다.
Checkpointing(검사점 연산)은 기본적으로 주기억장치(Memory)에 존재하는 모든 로그 레코드와 변경된 데이터 페이지를 디스크에 반영하여, (디스크에 저장되어 있는) 데이터 상태와 (주기억장치에 저장되어 있는) 데이터 상태를 동일하게 하는 연산입니다.
Recovery Process - in main memory
시스템 장애가 발생하면, 로그와 디스크에 저장된 데이터만 존재하므로 이를 이용하여 시스템 회복을 하여야 합니다.
로그 기반 회복은 크게 두 가지로 분류할 수 있습니다.
- UNDO - 시스템 장애가 발생하였을 때, 로그를 이용하여 변경된 데이터를 원래 상태로 되돌리는 방식
- REDO - 시스템 장애가 발생하였을 때, 로그를 이용하여 변경된 데이터를 디스크에 반영하는 방식
회복 과정은 다음과 같습니다.
- “undo-list”와 “redo-list”를 initialize합니다. (empty 하게)
- 가장 최근의 checkpoint 레코드가 나올때까지 올라갑니다. (log를 가장 최근시점부터 거슬러 올라가며 읽음)
- 올라가면서 undo-list와 redo-list에 레코드를 추가합니다.
- 만약 (레코드가
<Ti commit>이면) → Ti를 “redo-list”에 추가 - 만약 (레코드가
<Ti start>이면) && (Ti가 “redo-list”에 없다면) → “undo-list”에 추가 - L에 있는 모든 Ti에 대해, (만약 Ti가 “redo-list”에 없다면) → “undo-list”에 추가
- 만약 (레코드가
- “undo-list”에 속하는 트랜잭션에 대해 각 로그 레코드에 대해 실행 취소를 수행하고, “redo-list”에 속하는 트랜잭션에 대해 각 로그 레코드에 대해 다시 실행을 수행합니다.
UNDO를 먼저 수행하고, REDO를 수행하는 방식으로 회복을 수행합니다. (상식적으로 생각해보면, REDO한 뒤에 UNDO를 수행하면 REDO한 것이 무의미해지기 때문입니다.)
Buffer Management
데이터베이스 시스템이 버퍼를 사용하는 이유는 디스크와 메인 메모리의 속도 차이 때문입니다. 디스크는 메인 메모리에 비해 속도가 느리기 때문에, 디스크에 있는 데이터를 메인 메모리에 복사하여 사용자가 데이터에 접근할 때 빠르게 접근할 수 있도록 합니다.
해당 섹션에서는 이 버퍼를 어떻게 관리하는지에 대해 다룹니다.
버퍼 관리에서 가장 중요한 것은 버퍼 교체 정책입니다. 버퍼 교체 정책은 버퍼에 있는 데이터 중 어떤 데이터를 버릴지 결정하는 정책입니다. 선택된 버퍼는 더 이상 메모리 버퍼 공간을 차지하지 않게 됩니다. (단, 그 블록 내용이 변경되었으면 디스크에 그 내용을 반영해야 합니다)
가장 널리 사용되는 방식은 LRU(Least Recently Used) 방식입니다. LRU 방식은 가장 오랫동안 사용되지 않은 데이터를 버퍼에서 제거하는 방식입니다.
LRU 방식의 기본 아이디어는 블록에 대한 과거 접근 패턴이 미래에도 적용될 것이라는 가정입니다.
이 가정은 대부분의 경우에 유효하지만, 특정 상황에서는 잘못된 결정을 내릴 수 있습니다.
LRU 방식이 데이터베이스 환경에서 적절하지 않다는 지적은 문헌에 많이 나와 있으나, 아직까지 이를 대체하는 효과적인 버퍼 교체 방식이 없는 것도 사실입니다.
LRU 버퍼 교체 정책 외에도 다양한 버퍼 교체 정책이 존재합니다.
- Pinned block
- Toss-immediate strategy
- MRU(Most Recently Used) strategy
Data Page Buffering
데이터베이스 시스템에서는 데이터를 페이지 단위로 관리합니다. 앞서 설명했던 Buffering(디스크에 있는 데이터를 시스템 버퍼에 복사하는 과정)도 페이지 단위로 복사합니다.
Data Block을 Disk에 쓸 때 해당 블록이 수정/변경/갱신되면 안되기 때문에, Before writing a data item, transaction acquires exclusive lock on block containing the data item.
Lock can be released once the write is completed. Such locks held for short duration are called latches
latch는 데이터 블록을 메모리에 쓸 때, 해당 블록이 다른 블록에 의해 교체되지 않도록 하는 기능입니다.
latch와 기존에 우리가 배웠던 database lock은 다른 개념입니다.
- latch는 운영체제가 지원하는 기능으로서 다수 사용자를 위한 소프트웨어에서 공유 데이터 접근을 제어하기 위하여 사용됩니다.
- lock은 데이터베이스 시스템이 관리하는 데이터에 대한 concurrency control입니다. 일반적으로 다수의 록 모드가 존재하며, 록 유지 시간은 래치보다는 깁니다. 구현 관점에서 보면, 데이터베이스 록은 운영체제의 래치를 이용하여 구현됩니다.
DB buffer 구현은 크게 두 가지 방식으로 구현할 수 있습니다.
- Real main-memory buffer
- Virtual memory buffer
보통 DB buffer는 2번 방식으로 구현합니다.
실제 메모리(RAM) 즉 물리 메모리가 가득 차게 된다면 프로세스 더 이상 이어가지 못하고 종료가 됩니다. 이를 방지하고자 부족한 메모리를 하드 디스크 공간으로 할당한 스왑 메모리(Virtual memory)를 통하여 진행을 하는 것입니다.
하지만 2번을 사용하면 Dual paging problem이 발생할 수 있습니다.
1. 프로그램이 실행되고 있는 동안 운영 체제는 가상 메모리를 관리하고 페이지 교체 알고리즘을 사용하여 메모리를 관리합니다.
2. 한 페이지가 메모리에서 제거되고 스왑 파일에 기록될 때, 해당 페이지는 물리적인 메모리에서 해제됩니다.
3. 그러나 동시에 프로그램은 이전에 스왑된 페이지를 다시 요청할 수 있습니다. 이때 운영 체제는 해당 페이지를 다시 물리 메모리로 로드해야 합니다.
4. 이 경우 페이지가 두 번 스왑되는데, 즉, 물리 메모리에서 스왑 파일로, 그리고 다시 스왑 파일에서 물리 메모리로 이동됩니다.
Dual paging 문제는 데이터베이스 시스템이 특정 블록을 디스크에 output 하려고 할 때,
해당 블록이 이미 디스크 swap 영역에 존재하여 이를 메모리 상으로 input한 후
이를 다시 디스크에 output하는 현상인데, 일반적인 운영체제에서는 dual paging 문제가 발생할 수 있습니다.
Dual paging 문제를 해결하려면, 운영체제가 블록을 swap 영역에 output 하지 말고 데이터베이스 시스템과의 협의 하에 데이터베이스 영역에 output을 하여야 합니다.
Slotted Page Structure
슬롯 페이지 구조는 데이터베이스에서 사용되는 데이터 페이지의 형식 중 하나입니다. 이 구조는 페이지 내에 데이터 레코드를 저장하는 방법을 정의합니다.
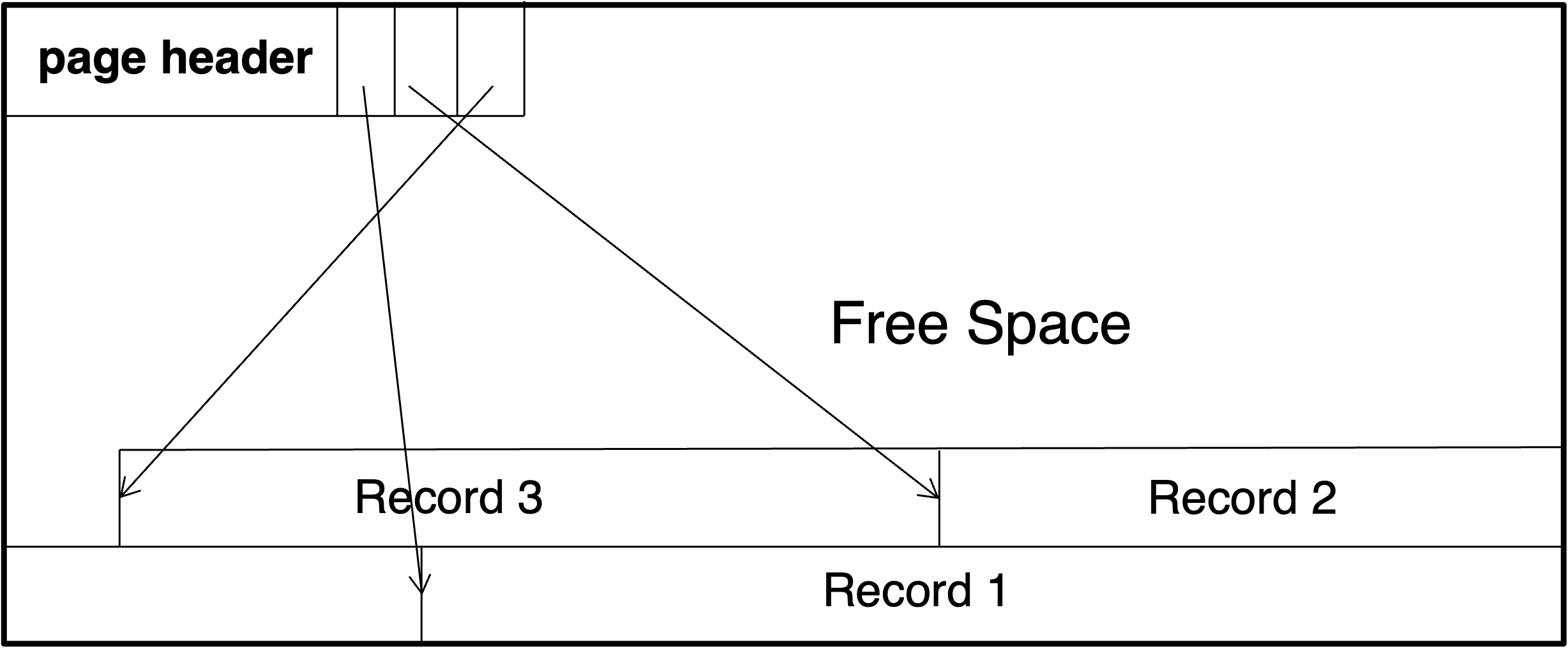
슬롯형 페이지 구조에서 각 페이지는 고정된 크기를 가지며, 이 페이지는 slot으로 나누어져 있습니다. (각 slot은 하나의 데이터 레코드를 저장합니다)
기본적으로 가변길이 레코드를 지원하는 구조입니다.
- 페이지 헤더가 나오고,
- 그 다음은 정해진 수의 slot이 나옵니다.
- 각 slot는 그 페이지에 저장되는 레코드의 주소를 가지고 있습니다.
- 레코드는 페이지 끝에서부터 저장되기 때문에, 페이지 중간에는 미사용 공간이 존재할 수 있습니다.
페이지 헤더에는 다양한 정보가 저장될 수 있습니다.
- ex) 페이지 id, 소유자, 여부공간, 페이지 마지막 수정 시간, 본 페이지와 관련된 로그 페이지 id…
Steal vs. Force Policy
회복 알고리즘은 데이터 페이지 처리 방식에 따라 force/steal 조건에 따라 4가지 방식이 가능합니다.
- No-force, No-steal
- Force, No-steal
- No-force, Steal
- Force, Steal
Force : 트랜잭션이 commit되기 전에 데이터 페이지를 디스크에 쓰는 방식입니다. 이때도 WAL을 지켜야 합니다.
Steal : 트랜잭션이 commit되기 전에 다른 트랜잭션이 해당 페이지를 읽을 수 있게 하는 방식입니다.
No-force : 트랜잭션이 commit되기 전에 데이터 페이지를 디스크에 쓰지 않는 방식입니다.
No-steal : 트랜잭션이 commit되기 전에 다른 트랜잭션이 해당 페이지를 읽지 못하게 하는 방식입니다.
이론적으로 4가지 방식이 가능하나, 실질적으로는 Steal/Not Force 방식이 사용됩니다.

Log-Based Recovery - in main memory
Log Block Buffering
Log record를 저장하는 로그 블록도 데이터 블록과 마찬가지로 Buffering을 합니다. (우선 메인 메모리의 buffer에 저장을 하며, 적절한 시점이 되면 storage에 있는 log db에 저장) 그런데 만약 버퍼에 있는 로그 블록이 꽉 차게 되면, 버퍼에 있는 로그 블록을 디스크에 쓰게 됩니다.
Log records are output to stable storage when a block of log records in the buffer is full or a log force operation is executed
log force operation은 버퍼에 있는 모든 log record를 디스크(stable storage)에 쓰는 연산입니다. 이 연산은 transaction이 commit하기 전에 실행되어야 합니다.
Group commit
Log record를 쓰는 연산은 시간이 오래 걸리는 연산이므로, 시스템 전체의 효율성을 위해 group commit이라는 방식을 사용합니다. Log block을 transaction이 완료될 때마다 쓰는 것이 아니라, 다수의 log record가 log block을 거의 채울 때까지 기다렸다가 한 번에 쓰는 방식입니다.
log record를 buffering하는 경우 지켜야 하는 규칙이 있습니다.
- Log record는 생성된 순서대로 디스크에 써져야 합니다.
- Transaction T(i)는 commit되기 전에 log record
<Ti commit>이 먼저 디스크에 써져야 합니다. - 버퍼에 있는 data block이 디스크에 쓰여지기 전에, 해당 data block과 관련된 log record가 먼저 디스크에 써져야 합니다.
- 이를 Write-Ahead Logging, 즉 WAL이라고 합니다.
Recovery Algorithm
기존에 살펴봤던 Recovery approach를 보다 향상시킬 수 있습니다.
정상적으로 Transaction이 수행되고 있을 때 roll back이 일어나면, 해당 Transaction의 효과를 없애기 위해서 UNDO 작업을 수행하게 됩니다. 이때 해당 UNDO 작업에 대하여 Log record를 발생시키게 됩니다.
이러한 Log record를 Compensation Log Record(CLR)라고 합니다.
Transaction 수행 중 장애가 발생 시 회복 과정은 다음과 같습니다.
- Redo phase.
- replay updates of all transactions whether they committed, aborted, or are incomplete
- Undo phase.
- undo all incomplete transactions
Redo phase에서는 가장 최신의 checkpoint record부터 모든 트랜잭션을 re-play합니다.
<Ti, Xj, V1, V2>레코드가 있을 때, V1을 V2로 바꾸는 작업을 수행합니다.<Ti start>레코드가 있다면, 해당 트랜잭션을 “undo-list”에 추가합니다.<Ti commit>이나<Ti abort>레코드가 있다면, 해당 트랜잭션을 “undo-list”에 추가합니다.
Undo phase에서는 “undo-list”에 있는 트랜잭션들에 대해 undo 작업을 수행합니다. “undo-list”에 있는 트랜잭션에 아래와 같은 레코드가 있을 때, 해당 작업을 수행합니다.
<Ti, Xj, V1, V2>레코드가 있다면, Xj에 V1을 다시 쓰는 작업을 수행합니다.
이후 CLR 레코드를 발생시킵니다. (<Ti, Xj, V1>)<Ti start>레코드가 있다면,<Ti abort>log record를 생성합니다. 그리고 해당 트랜잭션을 “undo-list”에서 제거합니다.- “undo-list”에 있는 모든 트랜잭션들은
<Ti start>레코드가 존재합니다.
- “undo-list”에 있는 모든 트랜잭션들은
Undo시에도 발생하는 log record들을 기록해야 합니다.
앞서 설명한 방법은 undo 할 트랜잭션도 redo를 하게 되는데, 이를 repeating history라고 합니다.
이전의 Recovery approach는 undo → redo를 수행하게 되는데, 이 경우 undo-list와 redo-list를 구분하고, undo-list가 빌 때까지 undo를 수행하고, 이후 redo를 수행하는 방식이기 때문에 시간이 오래 걸립니다.
하지만 repeating history 방식은 redo → undo를 수행하게 되므로, redo를 진행하며 undo-list를 만들어 나갈 수 있습니다. 이러한 방식은 시간을 단축시킬 수 있습니다.
Fuzzy Checkpointing
Checkpointing은 데이터베이스 시스템이 정상적으로 동작하고 있는 시점을 기록하는 것입니다. 그러나 checkpointing을 수행하는 동안에도 트랜잭션은 계속 수행됩니다. 이러한 상황에서 checkpointing을 수행하면, checkpoint 이후에 발생한 트랜잭션은 checkpoint에 반영되지 않습니다. 이를 해결하기 위해 Fuzzy Checkpointing이라는 방식을 사용합니다.
검사점이 진행되는 동안 모든 데이터베이스 연산을 정지시키지 말고 일반 데이터베이스 연산이 수행하도록 허용하는 검사점을 퍼지 검사점(fuzzy checkpointing) 방식이라고 합니다.
Fuzzy Checkpointing 방식은 다음과 같습니다.
- 일시적으로 트랜잭션을 중단합니다.
-
log record를 생성하고 force log를 수행하여 디스크에 쓰는 작업을 수행합니다.(stable storage에 저장) - 메모리(buffer pool) 내에서 변경됐지만 아직 디스크에 기록되지 않은 페이지(“dirty page”)들의 list
M을 생성합니다. - 트랜잭션을 다시 시작합니다.
- list
M에 있는 변경된 페이지들을 백그라운드 작업으로 순차적으로 디스크에 기록합니다.- 이 기록 중에서 block이 update되면 안됩니다.
- WAL을 지켜야 합니다. (페이지가 디스크에 기록되기 전에 해당 변경사항을 나타내는 로그 레코드가 먼저 디스크에 안전하게 기록되어야 합니다.)
- checkpoint record log의 위치를 디스크의 정해진 위치(“last_checkpoint”)에 저장합니다.
Fuzzy Checkpointing을 사용하는 데이터베이스 시스템의 복구 과정은 다음과 같이 진행됩니다.
- 시스템은 디스크의 고정된 위치에 저장된 “last_checkpoint”를 참조하여 마지막으로 수행된 Fuzzy Checkpointing의 레코드 위치를 파악합니다.
- 이후, “last_checkpoint” 이후에 발생한 모든 로그 레코드를 디스크에서 읽어들입니다. 이 과정에서 복구 작업에 필요한 트랜잭션 내역을 파악하게 됩니다.
Log-Based Recovery - in disk
비휘발성 저장 매체(디스크 등) 또한 장애가 발생할 수 있습니다. 기본적으로 디스크 덤프 방식을 사용하여 디스크의 데이터를 복구합니다. 해당 기술은 체크포인팅과 유사하게 동작합니다.
- Periodically dump
- 데이터베이스의 전체 내용이 주기적으로 안정적인 저장소(보통 다른 디스크, 자기 테이프)에 덤프(복사)됩니다. 이는 일종의 데이터베이스 전체 스냅샷을 생성하는 것과 같습니다.
- A procedure similar to checkpointing
- 현재 주 메모리에 있는 모든 로그 레코드를 stable storage에 출력합니다.
- 이러한 덤프는 데이터베이스 시스템이 장애가 발생했을 때, 데이터베이스 시스템을 복구하는 데 사용됩니다.
- record
를 log화하여 stable storage에 저장합니다.
- dump를 수행하는 동안에는 어떠한 트랜잭션도 수행되지 않습니다.
디스크 고장으로부터 복구하기 위해 다음 단계를 따릅니다:
- 가장 최근의 dump로부터 데이터베이스를 복원합니다.
- 로그를 참조하고, dump 이후에 커밋된 모든 트랜잭션을 다시 실행합니다.
fuzzy checkpointing 방식과 유사하게
dump시에도 일반 데이터베이스 연산을 허용하는 fuzzy dump (또는 online dump) 방식이 존재합니다.
Remote Backup Systems
전쟁이 나거나 자연 재해로 인해 데이터베이스가 손실되는 경우를 대비하여 데이터베이스의 백업을 원격지에 저장하는 것을 말합니다. primary site와 backup site가 존재하며, primary site가 손상되었을 때 backup site로 전환하여 서비스를 계속할 수 있습니다. (가용성이 높다)
Detection of failure
backup site must detect when primary site has failed and take over the primary site’s responsibilities.
그렇다면 primary site가 죽었다는 것을 어떻게 알 수 있을까요? 이를 위해 Heartbeat라는 방식을 사용합니다. Heart-beat message는 primary site가 살아있는지 확인하는 방식으로, 일정 시간마다 primary site에게 신호를 보내어 응답을 받는 방식입니다.
Transfer of control
backup site가 primary site의 역할을 맡기 위해선, primary site의 데이터를 복사하여 사용해야 합니다. 이를 위해 Data Synchronization이 필요합니다.
Achieve synchronization by sending all log records from the primary site to the secondary site.
To take over control, backup site는 primary site로부터 가져온 data(복사해온 DB와 log records)를 이용하여 recovery를 수행합니다.
recovery를 진행하며
- completed transactions는 (backup site에서도 commit되어야 하므로) 다시 수행되고
- incomplete transactions는 rollback됩니다.
백업이 성공적으로 이루어지면, backup site는 new primary site가 되어 서비스를 제공합니다.
재난 시 backup site가 빠르게 제어권을 가지기 위해선 backup site가 primary site에서 받는 log records를 즉시 적용해야 하며, 이를 Hot-Spare configuration 라고 합니다.
Time to Commit
backup시 업데이트가 기록될 때까지 transaction commit을 지연하여 durability of updates를 보장합니다.
- log record가 backup site에 도달할 때까지 transaction이 commit되었다고 선언하면 안 됩니다.
- 낮은 수준의 durability를 허용하여 지연을 줄일 수 있습니다.
One-safe: transaction의 commit log 기록이 primary에 기록되는 즉시 commit.
- 백업이 대체되기 전에 업데이트가 도착하지 않을 수 있습니다.
Two-very-safe: transaction의 commit log 기록이 primary 및 backup에 기록될 때 커밋
- 양쪽 사이트 중 하나라도 실패하면 트랜잭션이 커밋되지 않기 때문에 가용성이 감소합니다.
Two-safe: 주 서버와 백업이 모두 활성 상태인 경우 Two-very-safe와 동일한 방식으로 진행합니다. 주 서버만 활성 상태인 경우, 트랜잭션은 주 서버에 커밋 로그 레코드가 기록된 즉시 커밋됩니다.
- Two-very-safe보다 더 나은 가용성을 제공합니다.
- One-safe에서의 트랜잭션 손실 문제를 피합니다.
Conclusion
데이터베이스 시스템에서는 데이터의 안정성을 위해 다양한 방법을 사용합니다.
Recovery가 잘 지켜지는 경우 reliability(신뢰성)가 높아지고, Backup이 잘 되는 경우 availability(가용성)가 높아집니다.