
OpenAI TTS 사용하기
OpenAI TTS 사용하기
면접을 준비할 때 텍스트를 음성으로 변환하여 듣는 방식이 이후 말하기를 준비하는 데 도움이 될 것 같아 보통 녹음기로 음성을 녹음하고 듣곤 했습니다.
최근에는 Perplexity의 TTS 기능을 접하게 되면서, 녹음 내용을 편하게 변경해서 들을 수 있다는 점에서 매우 편리함을 느꼈습니다. 녹음의 목소리도 굉장히 자연스러워서, 녹음을 하지 않고도 텍스트를 음성으로 변환하여 듣는 방법에 대해 긍정적인 인식을 가지게 되었습니다.
하지만 Perplexity의 TTS 기능은 여러 번 반복재생되는 것이 아닌, 한 번만 재생되는 것이 단점이었습니다. 시각장애인을 위한 음성 변환 목적이 강하다는 점에서, 반복적으로 듣는 것이 목적인 저에게는 완전히 적합하지 않았습니다. 그래서 TTS를 오디오 파일로 다운로드 받을 수 있는 방법을 알아보았고, OpenAI의 TTS를 사용해보기로 결정했습니다.
기존에 OpenAI의 Voice mode를 이용해 본 경험이 있어, OpenAI의 TTS 성능이 좋다는 것을 이미 알고 있었습니다.
OpenAI TTS Reference
- OpenAI TTS : OpenAI TTS 공식 문서
사이트에 설명이 되어있는 대로, python(curl | node)을 이용하여 OpenAI TTS를 사용할 수 있습니다.
주의 : API Key를 발급받은 후에 해당 기능을 사용할 수 있습니다. 사용할 때마다 요금이 부과됩니다.
python을 이용하여 OpenAI TTS를 테스트해보았습니다. 아래는 테스트한 코드입니다.
from pathlib import Path
from openai import OpenAI
# OpenAI 객체 생성 (실제 API 키로 대체 필요)
client = OpenAI(api_key="sk-...")
# 음성 파일 출력 경로 설정
speech_file_path = Path.cwd() / "speech.mp3"
# Text-to-Speech 요청 및 스트리밍 처리
response = client.audio.speech.with_streaming_response.create(
model="tts-1",
voice="nova",
input="Today is a wonderful day to build something people love!"
)
# 결과를 파일로 저장
with open(speech_file_path, "wb") as f:
for chunk in response.iter_bytes():
f.write(chunk)
print(f"Audio file saved to: {speech_file_path}")
위 코드를 실행하면, speech.mp3 파일이 생성되며, 해당 파일을 재생하면 텍스트를 음성으로 변환한 결과를 들을 수 있습니다.
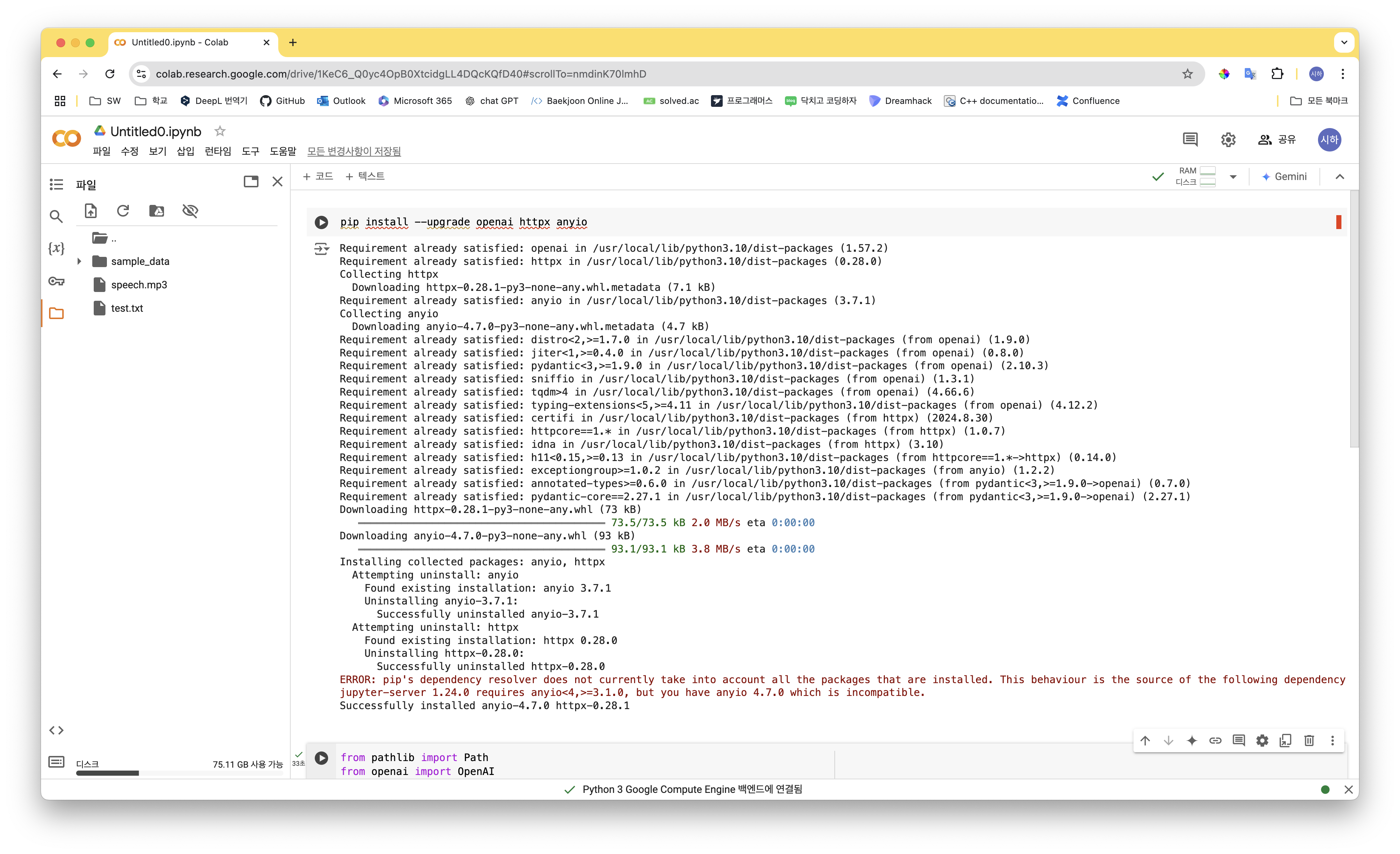 : OpenAI TTS를 이용하여 텍스트를 음성으로 변환한 결과.
: OpenAI TTS를 이용하여 텍스트를 음성으로 변환한 결과. pip install --upgrade openai httpx anyio 명령어로 필요한 패키지를 설치한 뒤 코드를 실행하였습니다.
이후 제가 변환하고 싶은 텍스트를 별도의 txt 파일에서 read하여 해당 content를 input으로 넣어주었더니, 다음과 같은 에러가 발생했습니다.
---------------------------------------------------------------------------
BadRequestError Traceback (most recent call last)
<ipython-input-5-a815c581eed0> in <cell line: 13>()
11 text_content = text_file.read()
12
---> 13 response = client.audio.speech.create(
14 model="tts-1",
15 voice="nova",
3 frames
/usr/local/lib/python3.10/dist-packages/openai/_base_client.py in _request(self, cast_to, options, retries_taken, stream, stream_cls)
1059
1060 log.debug("Re-raising status error")
-> 1061 raise self._make_status_error_from_response(err.response) from None
1062
1063 return self._process_response(
BadRequestError: Error code: 400 - {'error': {'message': '[{\'type\': \'string_too_long\', \'loc\': (\'body\', \'input\'), \'msg\': \'String should have at most 4096 characters\', \'input\': "\\nI am an applicant deeply interested in efficient system management and stable infrastructure operations. During university, I explored a variety of development fields, including frontend, backend, AI, embedded systems, and web/app development...
입력 텍스트(input)의 길이가 허용된 최대 문자 수인 4096자를 초과했기 때문에 발생한 에러였습니다. 이를 해결하기 위해 입력 텍스트를 4096자로 나누어서 요청을 보내는 방법을 사용했습니다.
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="sk-...")
# 읽어들일 텍스트 파일 경로 설정
text_file_path = Path.cwd() / "test.txt"
# 텍스트 파일 읽기
with open(text_file_path, "r", encoding="utf-8") as text_file:
text_content = text_file.read()
# 음성 파일 출력 경로 설정
speech_file_path = Path.cwd() / "speech.mp3"
# 4096자 이하로 텍스트 분할
MAX_LENGTH = 4096
text_chunks = [text_content[i:i + MAX_LENGTH] for i in range(0, len(text_content), MAX_LENGTH)]
# 분할된 텍스트로 요청
with open(speech_file_path, "wb") as f:
for chunk in text_chunks:
response = client.audio.speech.create(
model="tts-1",
voice="nova",
input=chunk
)
for byte_chunk in response.iter_bytes():
f.write(byte_chunk)
print(f"Audio file saved to: {speech_file_path}")
위 코드를 실행하면, test.txt 파일에 있는 텍스트를 4096자로 나누어서 음성 파일로 변환하여 speech.mp3 파일로 저장합니다. 이후 해당 파일을 재생하면, 텍스트를 음성으로 변환한 결과를 들을 수 있습니다.
마치며
OpenAI TTS를 사용하여 텍스트를 음성으로 변환하는 방법을 알아보았습니다. 이를 통해, 간단한 코드 작성만으로 텍스트를 음성으로 변환하여 들을 수 있게 되었습니다.
금액 또한 4KB 텍스트 기준 0.06달러로(한화 86원) 매우 저렴한 가격에 사용할 수 있어, 효율적으로 사용할 수 있을 것 같습니다.
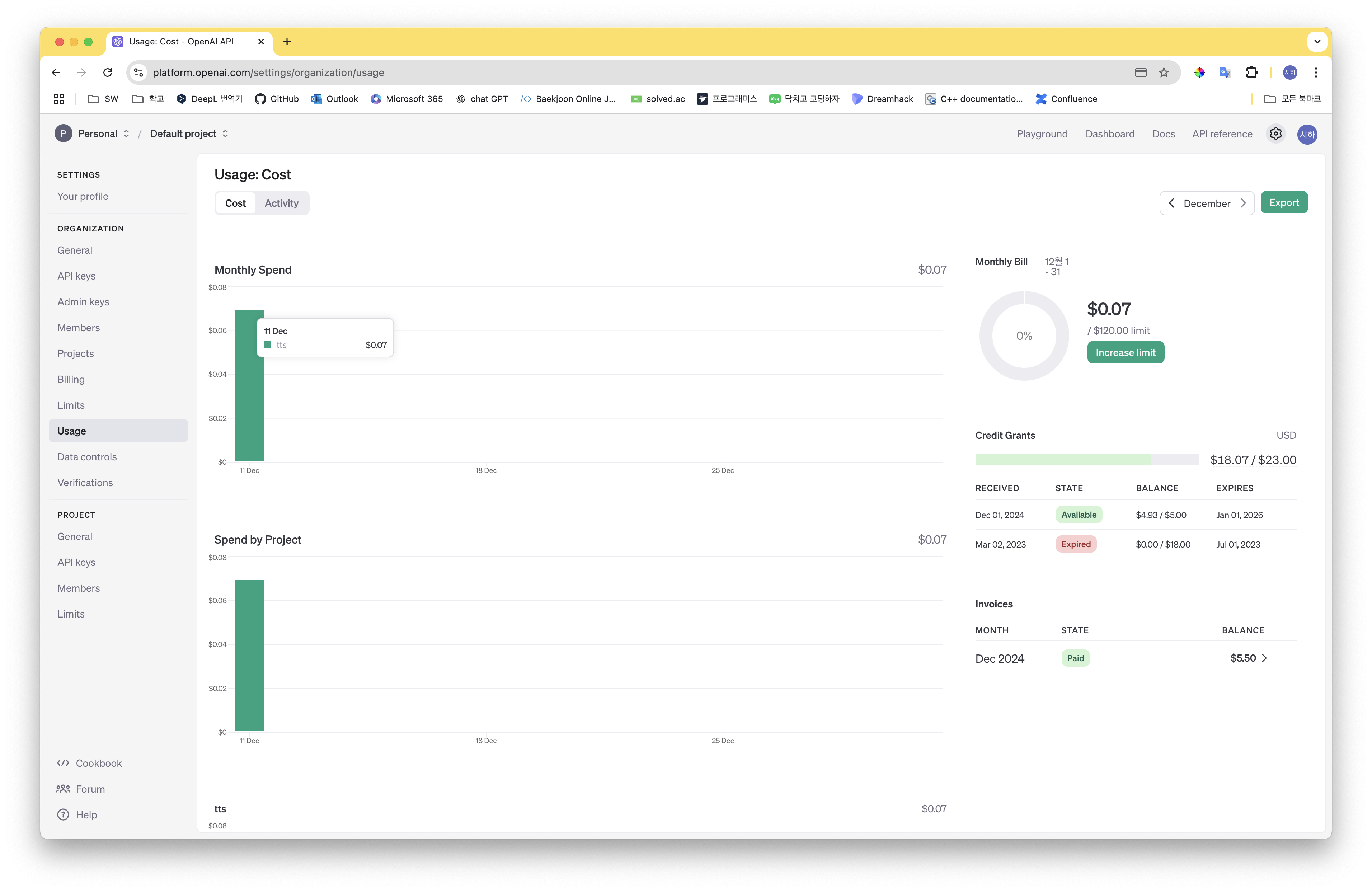 : OpenAI TTS의 가격은 4KB 텍스트 기준 0.06달러로 매우 저렴한 가격에 사용할 수 있습니다.
이제는 OpenAI TTS를 이용하여 텍스트를 음성으로 변환하여 듣는 방법을 통해, 더욱 효율적으로 시간을 활용할 수 있을 것 같습니다.
: OpenAI TTS의 가격은 4KB 텍스트 기준 0.06달러로 매우 저렴한 가격에 사용할 수 있습니다.
이제는 OpenAI TTS를 이용하여 텍스트를 음성으로 변환하여 듣는 방법을 통해, 더욱 효율적으로 시간을 활용할 수 있을 것 같습니다.